

Raise your hand if you think a Status Page for a service you provide or use is automatically updated
Auth0 had significant API outages on April 20, 2021 that lasted from about 15:30 UTC. until 19:20 UTC. This impacted many services, including ours.
Outages happen; that’s not the problem. But what happened around the reporting of it, and the communication of the outage to users, is a symptom of a wider problem in the tech sector.
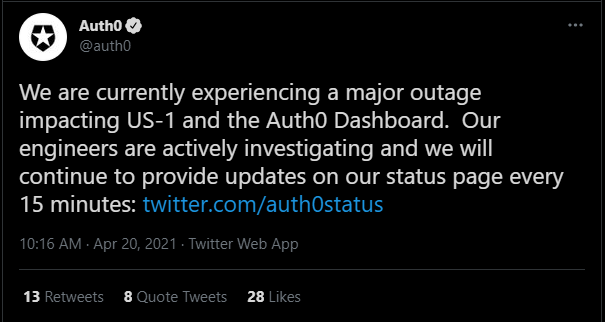
Auth0 started reporting the outage minutes after it had started. But rather than admitting to a widespread outage, they referred to “an increased error rate.” For a large number of users, that “increased error rate” translated to a total lack of service manifesting as a 502/504 Bad Gateway/Gateway Timeout error from the APIs used to log in and authenticate users.
Companies use StatusPage to share service performance and availability data with their users and clients.
However, for about an hour, the Auth0 Status Page was offline – presumably affected by the same API outages affecting the rest of their service. The irony that StatusPage itself was clearly being affected by the same problems it’s supposed to monitor was not lost on us.
When the Status Page came back up, the graphical view of the status page was still showing a 15-minute outage – THREE hours after the problems started.

There was no “official” notification of a major outage until 10:16 a.m. PST, almost two hours after the outage started.
What does this tell us about API outages (and other problems)?
A LOT of people, including a lot of our clients, use StatusPage for communicating with users about performance issues, API outages and other problems. But what a lot of our clients clearly do not understand is that StatusPage is not automatically linked to their monitoring.
The way StatusPage and most similar products work is that a HUMAN must change the status when they become aware of a problem. And to be fair, Atlassian doesn’t hide this fact.
So StatusPage does not, in fact, show users automatically updated live metrics from the APIs that are impacted by an outage, what that looks like, or when the problem actually started. It needs a human being to have the presence of mind in the middle of an outage to update their StatusPage manually.
In the case of this outage, Auth0 started to update their own Status Page about 60+ minutes in. I can only imagine what kind of confusion this must have caused to the many users who treat those status pages as gospel.
Then there’s the Catch-22 of StatusPage – if the system you use to communicate problems is tied to your own services, you might not be able to display that there is a problem because you’re affected by the problem you need to tell your users about in the first place!
This leads to what I can only call DevOps by Twitter. This is a problem that has impacted many companies including Google and AWS.
Depending on social media to find out about outages is bad policy and prone to failures. By the time the social media team and engineering get on the same page, things are probably already bad.
Then there is how YOU communicate once you get control of the situation. “Increased errors” may be 100% correct but is UTTERLY MEANINGLESS to any user who can’t even log in to the system.
Outage alerts and notifications are best done externally from your core architecture, just in case something happens to it or the connection between it and the outside world.
Canaries in Coal Mines
APIs are the ultimate canary. If you can’t run real, authenticated API calls into your systems and process data, then your systems are down. If you’re basing your monitoring strategy on pings or internal logs alone, you’ll have problems.
In the case of the Auth0 outage, the status page was ultimately updated that they had detected the problem and were investigating at 15:43UTC. We were already able to report on the issue a full hour before the problems became public – and long before Auth0 issued a statement acknowledging the issues.
That is already too long.

A Sector-Wide Problem with API Outages and Monitoring
This isn’t the first time this has happened, and it won’t be the last. But providers need to be transparent about the time events start and the nature of the issues.
Which brings us back to StatusPage from Atlassian.
We have been told by many prospective clients that they don’t need APImetrics (or a tool like us) because StatusPage shows the status of an API they provide or consume already. The fact is this: there is a disconnect between the perception of a product like StatusPage and what it actually does. And it’s clear to us that some teams are quite happy to hide behind that.
And now we’re back, finally to that question I started with: If you’re a manager, do you think a status page shows the real-time status of services?
Go on, be truthful now: you thought it was an automatic, accurate thing, didn’t you? You thought what you see on another provider’s status page was a real view of how things were working?
We’re not calling out StatusPage. Again, Atlassian has always been clear about their service and how it works.
But now that you know how it works, how does it make you feel to know that you’re depending on something that is up to your own team or a provider’s team to update?
And if a service has automated the process, don’t automate it with something that doesn’t accurately track availability.
What else isn’t being accurately reported?
What to do about (API) Outages
No service is 100% reliable, we know that – you will never avoid API outages. But it is essential to be honest, transparent, and realistic about problems that might arise.
We have 4 simple take away thoughts on API Outages and monitoring:
- Understand what your existing monitoring does and PLUG any gaps
- Have redundancy in the alerting and monitoring structure – the more monitoring, from different sources, ideally outside your stack, the better
- Monitor from where your customers are and from what they use, not from what is convenient to you – it’s also possible everything looks great internally but not from where customers and users are
- Get out ahead of issues and be honest and open about them
A New Approach…
Monitoring as a Service – Code Free DevOps
With API.expert, APImetrics is trying something different. Providing a simple to use, preconfigured library of critical APIs we monitor, designed in such a way that you can taken them onboard and be up and running on your own probes, using your own Authentication in minutes rather than hours, and in a way that’s easy to track and maintain.
That way you will always have a backup service reporting how things are working that is trusted and independent.
We also have integrated reporting and automated data export so if our public dashboards are down, and yours are down, you can have backups generated from real data.
But even if you don’t want to use us – and you can always contact me for beta access to API.expert – use something.
Let’s not let this happen again.



