The Definitive Annual Cloud API Performance Industry Report from the team, ecosystem, and data behind APIContext

Data Scientist @ APContext





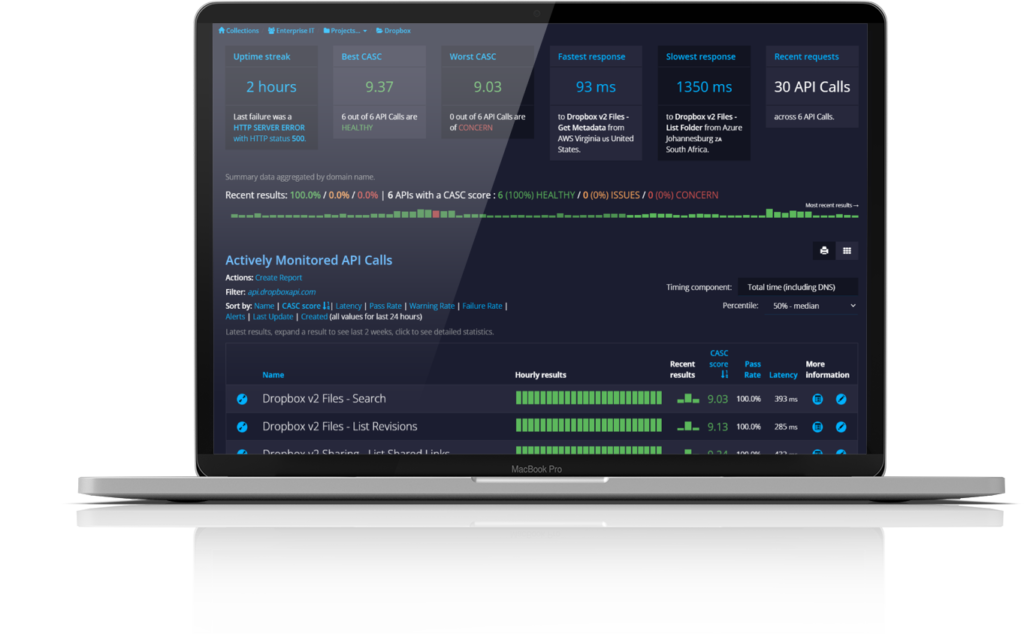
Some calls will be faster than others because of the nature of the backend processing involved, so total call duration, even over a sample size of tens of millions of calls, can only give a partial view of the behavior of the APIs.
In 2022, we added a huge number of fast calls for the Serinus Cloud Watch service calls. This had the effect of reducing the Total Time average, but it doesn’t affect the DNS Time, TCP Connect Time or SSL Handshake Time, which are determined by the cloud/region/location not by the call being made. Those three components are involved in the network setup of the call and are the same for all calls (they vary with cloud/region/ location and over time, but not by type of call).
The average total time has gone down, but the trends between clouds and regions remain. Remember, we are dealing with a snapshot from the data we have from which we can extract broad trends, not claiming that everything is like-for-like over a period of six years. We can only really do that for UK Open Banking.
- AWS was the fastest cloud by median total time from mid-2021 and the whole of 2022.
- Azure has been consistently the slowest cloud by median time since 2018.
- AWS’s median DNS Lookup Time has continued to fall and is now about 3 ms.
- The DNS Lookup Times for Azure and IBM Cloud have increased from mid-2021, bucking the long-term trend and also no longer demonstrating the marked quantized behavior seen since mid-2018. This suggests that there was some fundamental change made by Azure and IBM Cloud in 2021 to the configuration of their DNS services.
- Google’s DNS Lookup Time has only increased slightly in this period, but like Azure and IBM Cloud shows more variance and is no longer as obviously quantized suggesting that they too made configuration changes.
- DNS Lookup Time by region also showed a slight increase in 2022 and more variance, which reflects the changes made by Azure, Google, and IBM Cloud.
South America
South Asia