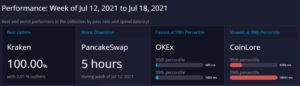
APImetrics, tomato pay and Finextra deliver a comprehensive report on UK Open Banking performance over the last year
APImetrics data shows Neobanks outperform CMA9 banks and traditional providers, suggesting technical debt presents a barrier to quality Open Banking solutions SEATTLE, WA, USA, October